Application Layering - A Pattern for Extensible Elixir Application Design
Introduction
When designing any application, the question is inevitably raised: “where should this code go?” Many times this answer isn’t readily available, resulting in code that ends up in a project’s junk drawer (like utils or models). If this happens enough, the codebase becomes tangled and the team’s ability to maintain the software over time is significantly decreased. This is not a sign of developer inexperience or “naming is hard” — instead it’s most likely a symptom of an application’s lack of structure.
The goal of this paper is to help Elixir developers learn how to structure large codebases so they can be maintainable, adaptable and extensible, without getting bogged down in a tangled web of interdependencies and technical cruft.
Background
Phoenix contexts are a good first step toward app organization and can work well for small scale apps. However as the app continues to grow, there is a tendency to keep all contexts as siblings in a single layer without a way to indicate the different levels of abstraction within the codebase. Things increase in complexity when business logic requires the assembly of data from multiple contexts and there’s no clear place where this logic should go.
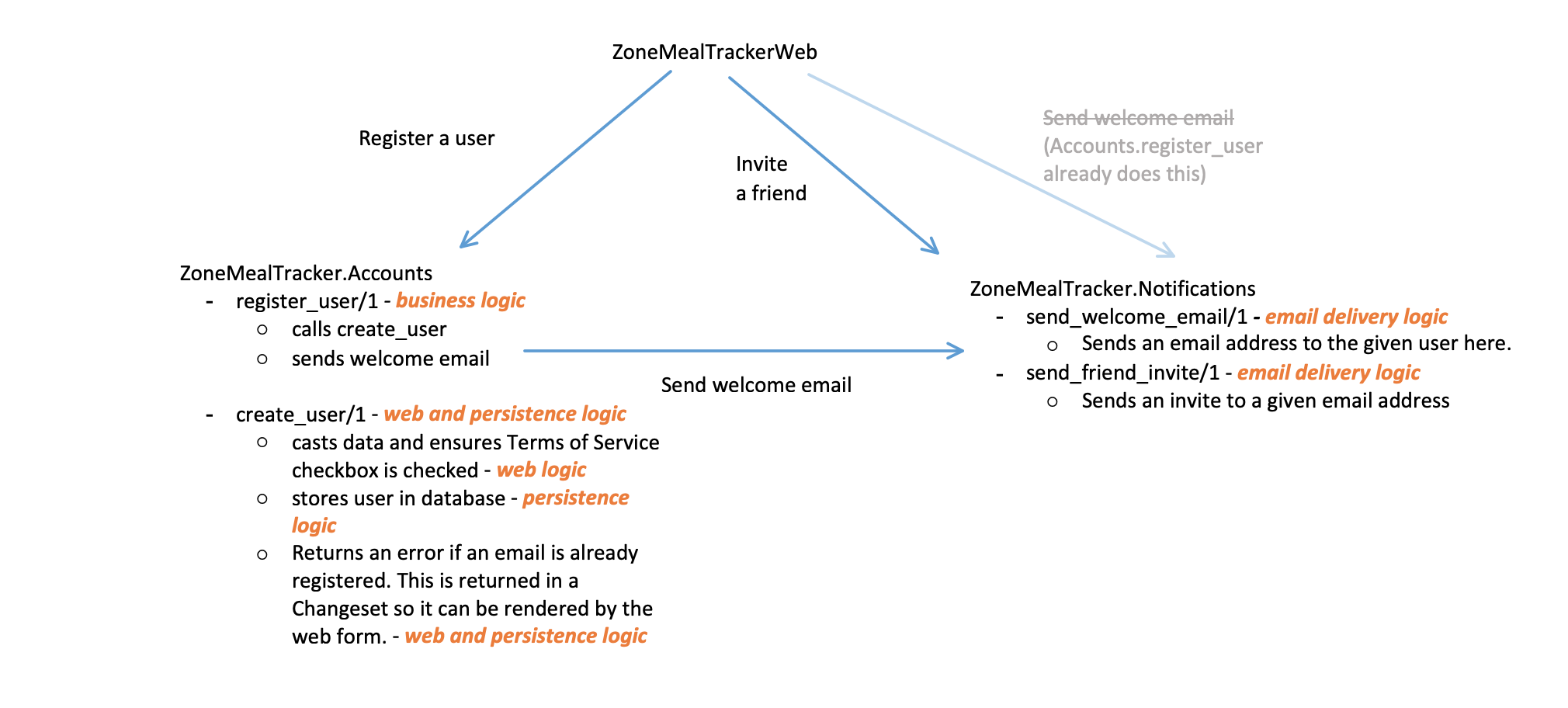
The real problem is there are many levels of abstraction which are all grouped into a single context. When levels of abstraction are mixed in the same module, or there is no place to put over-arching business logic, the codebase becomes muddy and difficult to reason about.
An alternative approach
Sometimes to come up with an alternative approach, one has to take several steps back and examine the problem from a different point of view.
Most libraries are a layer of abstraction over the functionality they provide. Developers write API client libraries, so they don’t have to think about HTTP requests, parsing responses, serializing data, and everything else that goes into an API client. The same idea applies with database adapters, web servers, hardware drivers, and many other libraries that provide a clean API to wrap potentially complex operations. They all hide layers of complexity so the developer can focus on writing their application without having to worry about low level concerns like opening a socket to a web server.
Even the libraries we use every day delegate complexity to other libraries that focus on lower levels of abstraction. As an example, let’s look at ecto_sql’s dependency tree.
ecto_sql ~> 3.0 (Hex package)
├── db_connection ~> 2.0 (Hex package)
│ └── connection ~> 1.0.2 (Hex package)
├── ecto ~> 3.1.0 (Hex package)
│ └── decimal ~> 1.6 (Hex package)
├── postgrex ~> 0.14.0 or ~> 0.15.0 (Hex package)
└── telemetry ~> 0.4.0 (Hex package)
ecto_sql provides an API for applications to interact with a database. The code inside ecto_sql focuses on writing application data into the database and reading it back out. However, when it comes to lower level concerns like maintaining database connections, connection pooling, metrics, and database specific communications, it calls out to other libraries that focus on those lower levels of abstraction.
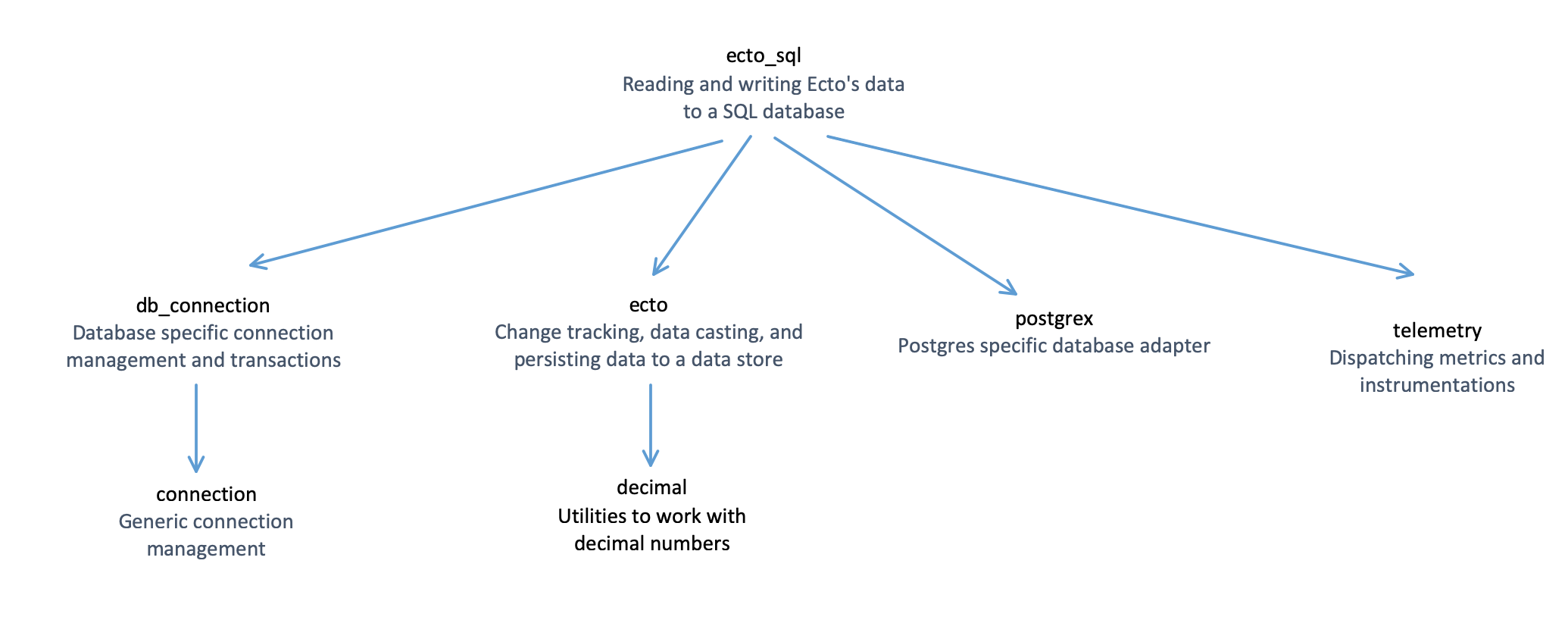
The idea of having libraries that focus on certain levels of abstraction is practiced fruitfully on a daily basis in the Elixir ecosystem. Library authors try to provide easy to use APIs that other applications can build on top of without getting bogged down in the levels of abstraction their library is meant to wrap. This sort of modularity and separation of concerns is a key factor in allowing developers to build better, more maintainable applications because they can focus on their business logic and delegate lower-level concerns to other libraries within the Elixir ecosystem.
Since the pattern of layering modular dependencies to isolate levels of abstraction works so well, why not extend this pattern into our application codebases so they have a tree of modular components that isolate logic to the appropriate levels of abstraction?
The Pattern
The pattern of Application Layering consists of two parts:
- Breaking an app into a tree of layers based on the app’s various levels of abstraction
- Allowing each layer’s implementation to be easily swapped with an alternative implementation to improve testability and increase adaptability to changing business requirements
As we go through this pattern, there is also an example repo that has been built using the techniques discussed: https://github.com/aaronrenner/zone-meal-tracker. This app has been refactored using some of the techniques discussed in later sections of this article, so you will have to go back in the commit history to see some of the earlier steps.
Break the app into multiple layers
It is common practice for developers in the Elixir/Phoenix community to split their projects into separate web and business logic apps through the use of Phoenix contexts. This was originally inspired by Lance Halvorsen’s talk Phoenix Is Not Your Application and further championed by the Phoenix framework’s code generators. This separation greatly simplifies the web app by allowing it to only focus on web concerns and be a thin interface to the underlying business application. This also allows developers to focus on the core logic of their project separately — an Elixir application that solves a business need.
Although we see huge gains by separating a web layer from the rest of the application, many projects stop with just these two layers. This can be fine for a small codebase, but in larger codebases this can lead to an application that becomes tangled and complicated.
The main idea behind Application Layering is to further decompose an app into multiple layers that isolate the application’s various levels of abstraction. This concept was originally introduced as the Layers pattern in Pattern-Oriented Software Architecture - Volume 1 in 1996. Some of this pattern’s benefits include:
- Understandability - Because layers are focused on a single level of abstraction, the code becomes easier to follow. For example, a business logic layer can focus on the process of registering a user (creating the user in the database, sending a welcome email, etc), without being cluttered with the lower-level details of SQL commands or email delivery.
- Maintainability - Code that is more understandable is simpler for a developer to update. When the application is separated into multiple layers, it’s much easier to understand where new logic should be written. Updates to how data is serialized when it’s being sent to an external API make sense to go in a low-level layer like an API client. Likewise, logic supporting new business processes should go in a higher-level business logic layer.
- Adaptability - Since parent layers communicate with child layers over clearly defined APIs, the implementation of a child layer can be replaced with an improved implementation that conforms to the same API. This allows for replacing the implementation of an entire layer without changes rippling up to the parent.
In Application Layering, we take the strict-variant of the Layers pattern (a layer can only be coupled to its direct child layers) and instead of creating application wide layers, we create a tree of child layers focused on the particular levels of abstraction that go into solving the task at hand.
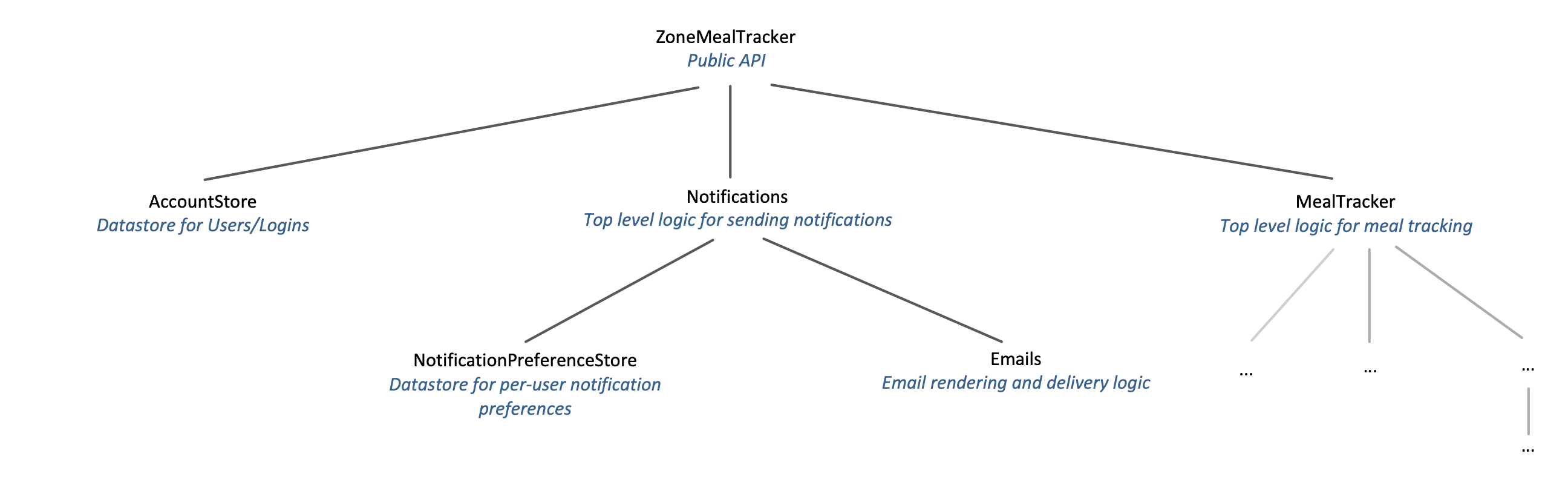
The great part of this “tree of layers” approach is each implementation can be decomposed into logical child modules, and each child module can be further decomposed into more child modules, if necessary. This decomposition naturally creates layers that move toward lower levels of abstraction. Business logic layers are able to stay simple, readable and flexible, even though they may be coordinating several complex lower-level layers. It also makes it easy for low level layers like API clients to be extracted into their own standalone libraries because they are decoupled from higher level layers.
Building a top-level API
Now that we’ve discussed the high level structure of Application layering, let’s look at how to implement it.
In order to make it clear what functionality our application exposes, we’ll treat our application’s top-level module as its Public API and the only place the outside world should interact with our code. Elixir’s Writing Documentation guide indicates that only our Public API should show up in the documentation and any internal functions/modules should be hidden with @moduledoc false. This allows a developer to get a clear view of the application’s contract with the outside world without getting confused by other internal modules that are actually implementation details.
It is very important to only have a single module (and its related structs) as the application’s public API for a couple of reasons:
- If additional modules are made public, it becomes very difficult to understand if a child module is part of the Public API or a lower-level implementation detail that’s only meant to be called internally.
- When adding a new business process that spans multiple components (like user registration which creates and account and sends a welcome notification), the top-level Public API module serves as a place to tie these components together into a single business process. Without a single, agreed upon place for the top level business logic, it becomes unclear where this logic should go.
Leveraging namespaces to indicate layers
If our top level module is the Public API, then child modules should only be one of two things:
- Struct-only modules referenced by the public API.
- Internal helper modules that are implementation details of the public API and not meant to be called publicly.
As mentioned previously, if we only document modules that are part of the public API, it’s easy to tell which modules and functions are public vs. internal.
defmodule ZoneMealTracker do
@moduledoc """
Public API for ZoneMealTracker application
"""
alias ZoneMealTracker.User
@doc """
Registers a new user with email and password.
"""
@spec register_user(String.t(), String.t()) ::
{:ok, User.t()} | {:error, :email_already_registered}
def register_user(email, password), do: #...
end
defmodule ZoneMealTracker.User do
@moduledoc """
User struct
"""
# This is a struct module used by the public API
defstruct [:id, :email]
@type id :: String.t()
@type t :: %__MODULE__{
id: id,
email: String.t()
}
end
defmodule ZoneMealTracker.Notifications do
@moduledoc false
# This module is just an implementation detail of ZoneMealTracker
# and not exposed on the public API. You can tell this by `@moduledoc false`
# and it doesn't define a struct.
#
# No modules other than ZoneMealTracker should call this because it's
# not part of the public API.
@spec send_welcome_message(User.t) do
end
The great thing about this approach is we’re exposing our functionality to the world through the Public API layer (module), and any child helper modules are part of a lower implementation layer that isn’t meant to be called by the public. This gives us the flexibility to organize and reorganize child modules in the implementation layer and have the security to know that they shouldn’t be called by any other module than their parent, the Public API.
In an effort to maintain simplicity, it’s important to keep functions with side-effects out of our struct-only modules. If we added ZoneMealTracker.User.fetch/1 to retrieve a user from the database, we are effectively splitting our public API across multiple modules, which leads to several problems including confusion around what our public API is, and not having a clear place for over-arching business logic. Instead, we can write ZoneMealTracker.fetch_user/1 which either has the lookup logic directly in the function, or delegates to a function on an internal data store module like ZoneMealTracker.UserStore.fetch/1.
Leveraging namespaces all the way down
Previously we used namespaces to indicate:
- The top level module is the Public API
- The child modules are either:
- Struct-only modules referenced by the public API.
- Internal helper modules that are implementation details of the public API and not meant to be called publicly.
The great thing about this pattern is we can repeat it many levels deep in our application and it still provides the same structure and guarantees.
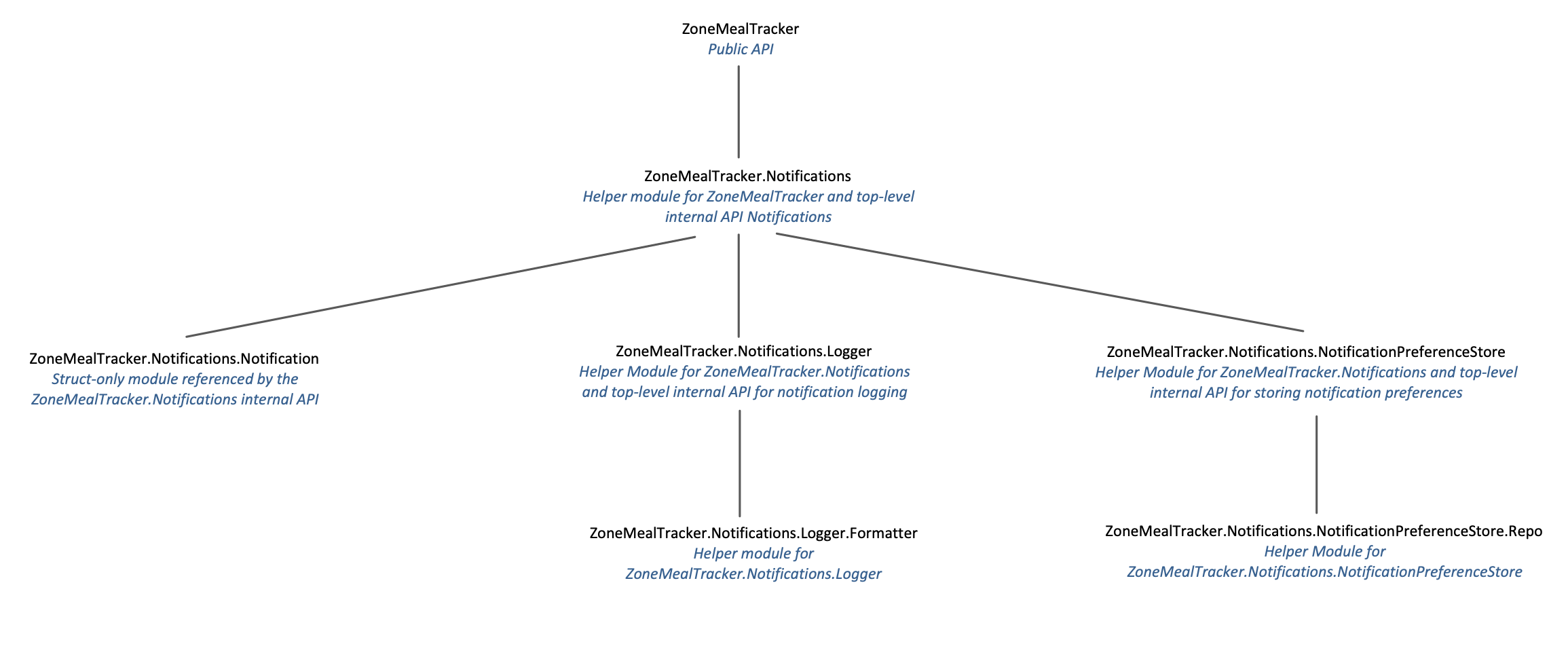
Really, the pattern we’re setting forth is:
- The current module is the API
- Child modules are either
- Structs referenced by the current module’s API
- Internal modules that are used by the API’s implementation
- Modules should only access their direct children. No accessing siblings, grandchildren, great grandchildren, etc.
- If you need to access siblings, then the logic should go in the next higher namespace
- If you need to access grandchildren, then the child module needs to provide an API for that functionality.
Naturally created layers
The great thing about using namespaces this way is it naturally creates layers. For example, ZoneMealTracker.Notifications.NotificationPreferenceStore is only focused on storing user preferences for the notifications system, where ZoneMealTracker is focused around the overall business logic of the application. As a developer, this layered structure provides a couple benefits:
- No need to look at the children of a module unless you care how the module’s logic is implemented. For example, if you’re calling the
ZoneMealTracker.register_user/2function, you should be able to trust that the user is registered properly. The only reason to look at its code or child modules is if you need to know how it registers the user. - Keeps the codebase easy to understand. If your boss says “now we need to send off metrics when a user is registered,”
ZoneMealTracker.register_user/2is a nice, logical place to integrate this new functionality. If this top-level public API wasn’t available, user registration may be placed on a traditional context likeZoneMealTracker.Accounts.register_user/1. However, this makes theZoneMealTracker.Accountsmodule more difficult to understand because some of its functions operate at the business logic layer, and others operate at the persistence layer. Now the developer has to keep in mind which functions are high level (business logic) and which functions are lower level (persistence logic) and call the functions that are appropriate to the level in which they are currently working. It’s much simpler if a module’s API only operates at a single level of abstraction.

Make implementations swappable
Now that the application has been layered through the use of namespaces and we have well-defined APIs on each layer, we can take this one step further and allow the code behind these APIs to be swapped out with different implementations.
Although the Layers pattern hints at being able to swap implementations when they mention “Exchangeability”, this concept is covered in more detail in the “Hexagonal Architecture” paper by Alistair Cockburn. Hexagonal architecture (aka ports and adapters) says in order to keep the application flexible, business logic should communicate to things in the outside world (databases, HTTP APIs, etc) over a well defined interface. This gives the developer a huge amount of flexibility, because once the well-defined interface is created, the current implementation can be replaced with any other implementation that also conforms to that well defined interface. In our case, each layer of the application communicates to the layers below it through these interfaces, and the implementations of these lower-level layers can be easily swapped without affecting any code in higher-level layers.
In hexagonal architecture diagrams, instead of talking about higher-level and lower-level layers they turn the diagram 90 degrees to the left and say:
- higher-level layers call the logic inside the hexagon through “left side ports” and
- the logic inside the hexagon calls lower-level layers through “right side ports”
The hexagon shape isn’t significant; it’s just an easy to draw shape where each flat side represents a port.
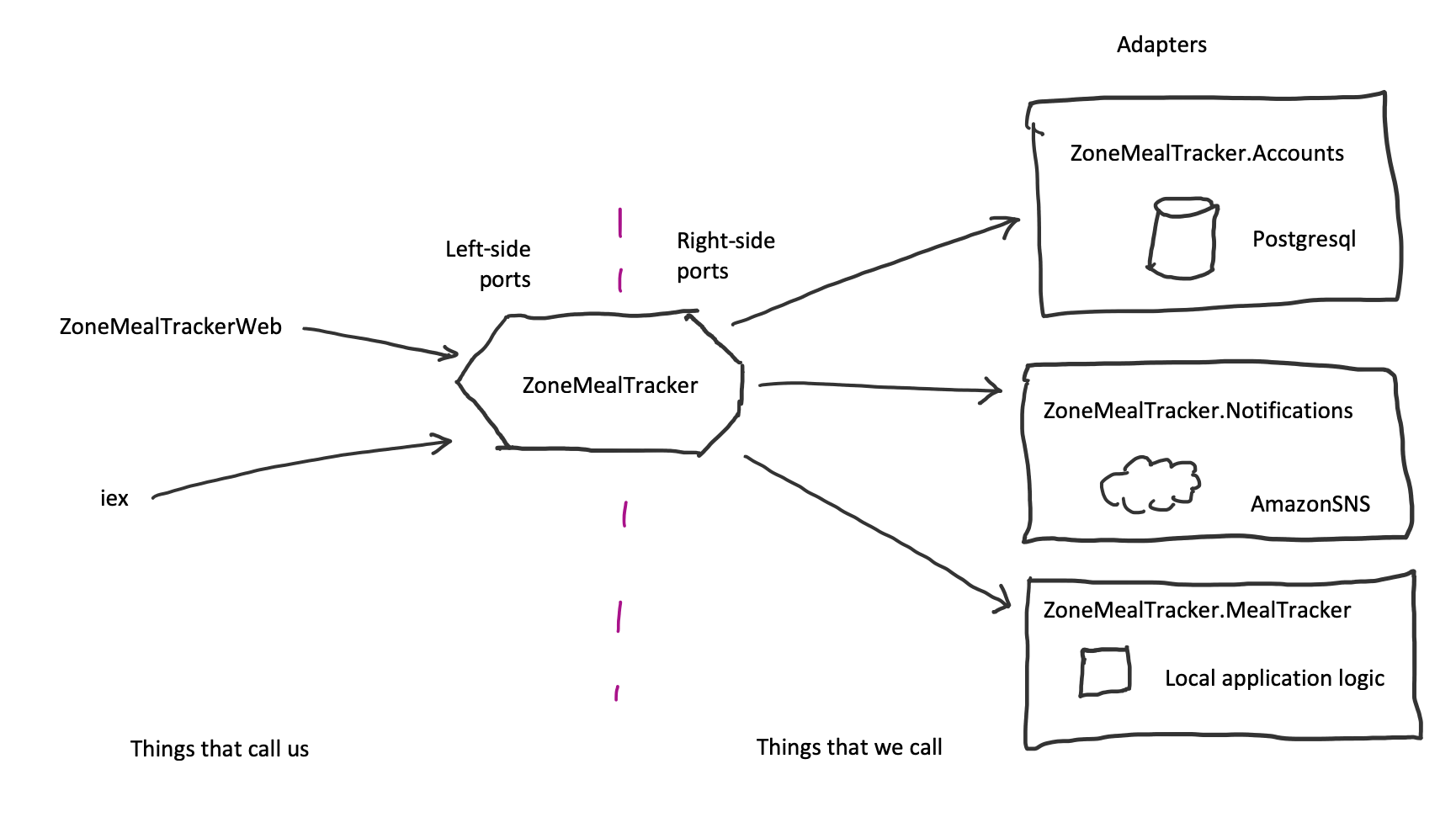
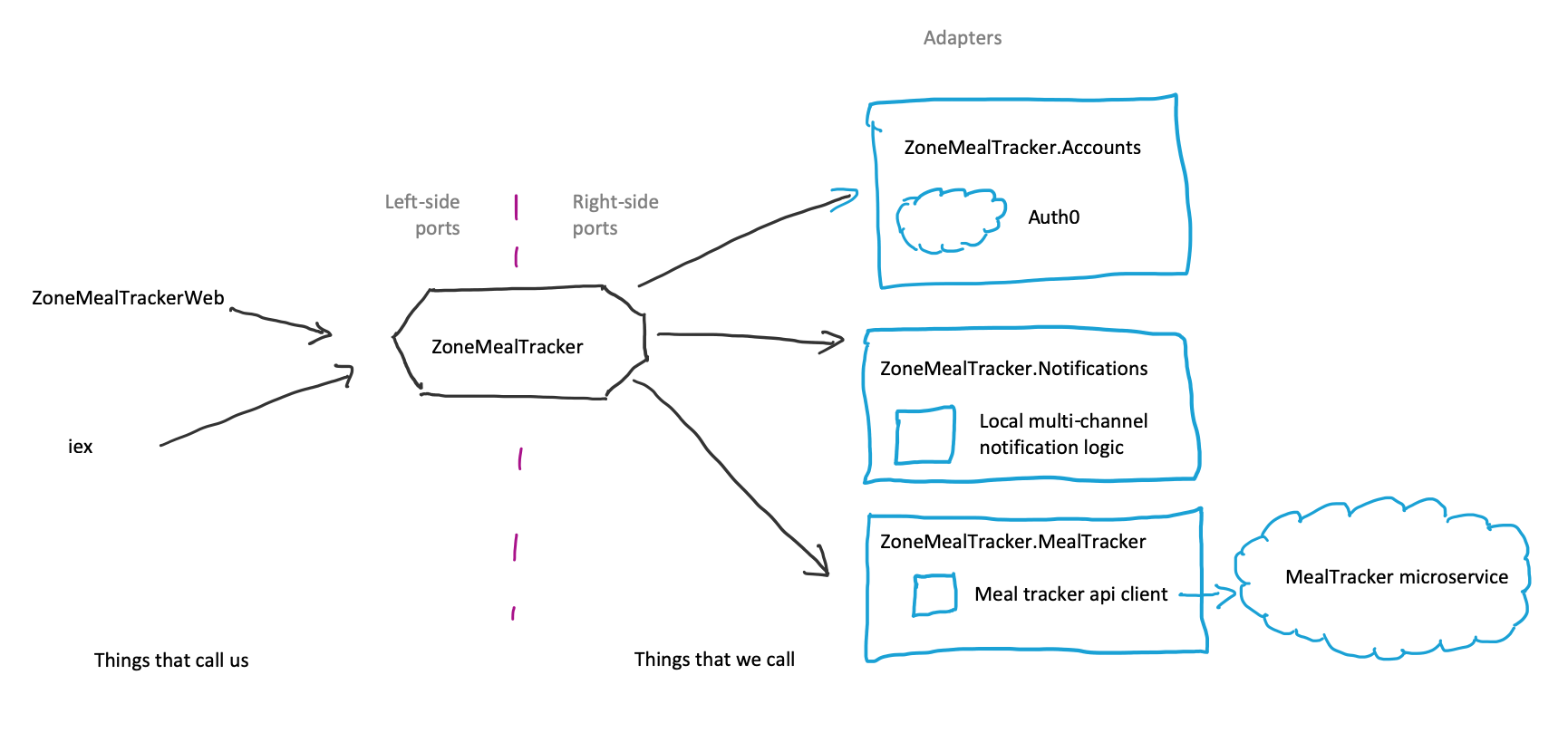
The power to swap implementations on the right side ports, allows us to:
- Easily unit test business logic without calling out to external services
- Build implementations of child layers that return fake data so higher layers of an app can be developed while other teams are still building out the lower layers
- Solidify the functions of the lower layer’s API without actually writing any lower layer implementation code. This allows us to defer technical decisions like which data store to use, how to structure database tables, etc. until we have a clearer understanding of the interface we need to provide.
- Easily adapt to changing business requirements. For example, when the business wants us to migrate to a new API provider, all we’d need to do is swap in a new implementation of that child layer. As long as the new implementation can provide the same code-level interface as the previous implementation, the new implementation can be swapped in without affecting anything upstream.
Mechanics of swapping out child layers in Elixir
Although having the ability to swap in different implementations sounds great, actually implementing it can be difficult. Here are a few ways I’ve tried:
- Injecting collaborating functions as optional parameters
- Looking up the current implementation before calling a function
- Calling an API module that delegates to the current implementation behind the scenes
For reference, here is an example register_user/2 function that we’ll modify using the different methods of swapping implementations.
@spec register_user(String.t(), String.t()) ::
{:ok, User.t()} | {:error, :email_already_registered}
def register_user(email, password) do
case AccountStore.create_user(email, password) do
{:ok, %User{id: user_id} = user} ->
:ok = Notifications.set_user_email(user_id, email)
:ok = Notifications.send_welcome_message(user_id)
{:ok, user}
{:error, :email_not_unique} ->
{:error, :email_already_registered}
end
end
Swapping approach: Injecting collaborating functions as optional parameters
This approach involves modifying a function to accept new parameters so the developer can swap implementations during test.
@type register_user_opt ::
{:create_user_fn, (String.t(), String.t() -> {:ok, User.t()} | {:error, Changeset.t}) |
{:set_primary_notification_email_fn, (String.t(), String.t() -> :ok)} |
{:send_welcome_message_fn, (String.t() -> :ok)}
@spec register_user(String.t(), String.t()) ::
{:ok, User.t()} | {:error, :email_already_registered}
def register_user(email, password, opts \\ []) do
create_user_fn = Keyword.get(opts, :create_user_fn, &AccountStore.create_user/2)
set_primary_notification_email_fn =
Keyword.get(opts, :set_primary_notification_email, &Notifications.set_user_email/2)
send_welcome_message_fn =
Keyword.get(opts, :send_welcome_message, &Notifications.send_welcome_message/1)
case create_user_fn.(email, password) do
{:ok, %User{id: user_id} user} ->
:ok = set_primary_notification_email_fn.(user_id, email)
:ok = send_welcome_message_fn.(user_id)
{:ok, user}
{:error, :email_not_unique} ->
{:error, :email_already_registered}
end
end
Benefits
- Low barrier to entry
- Allows collaborating functions to be swapped with any other implementation. Doesn’t require additional modules to be defined.
- Alternative implementations can be swapped in per function call. No global configuration in the application environment.
Drawbacks
- Quickly makes the function more complicated and harder to reason about
- Requires significant code changes
- Easy for mocks and alternative implementations to drift from what’s expected
- No dialyzer support
Swapping approach: Looking up the current implementation before calling a function
This approach involves looking up the module that contains the current implementation from the application environment. This happens in the module that’s calling the function.
@spec register_user(String.t(), String.t()) ::
{:ok, User.t()} | {:error, :email_already_registered}
def register_user(email, password) do
case account_store().create_user(email, password) do
{:ok, %User{id: user_id} = user} ->
:ok = notifications().set_user_email(user_id, email)
:ok = notifications().send_welcome_message(user_id)
{:ok, user}
{:error, :email_not_unique} ->
{:error, :email_already_registered}
end
end
defp account_store do
Application.get_env(:zone_meal_tracker, :account_store, AccountStore)
end
defp notifications do
Application.get_env(:zone_meal_tracker, :notifications, Notifications)
end
Benefits
- Compatible with Mox
Drawbacks
- Requires code changes when calling functions
- Doesn’t work with dialyzer because the module name is dynamically resolved
- Every caller module has to look up the current implementation themselves. This becomes a significant burden.
- The current implementation is controlled globally via the application environment. This makes it difficult for multiple implementations to be run in parallel
Swapping approach: Calling an API module that delegates to the current implementation behind the scenes
This approach lets client code continue to call the original module with no change. Instead, the original module is modified to delegate function calls to the current implementation. This approach basically splits the module’s public API from its implementation.
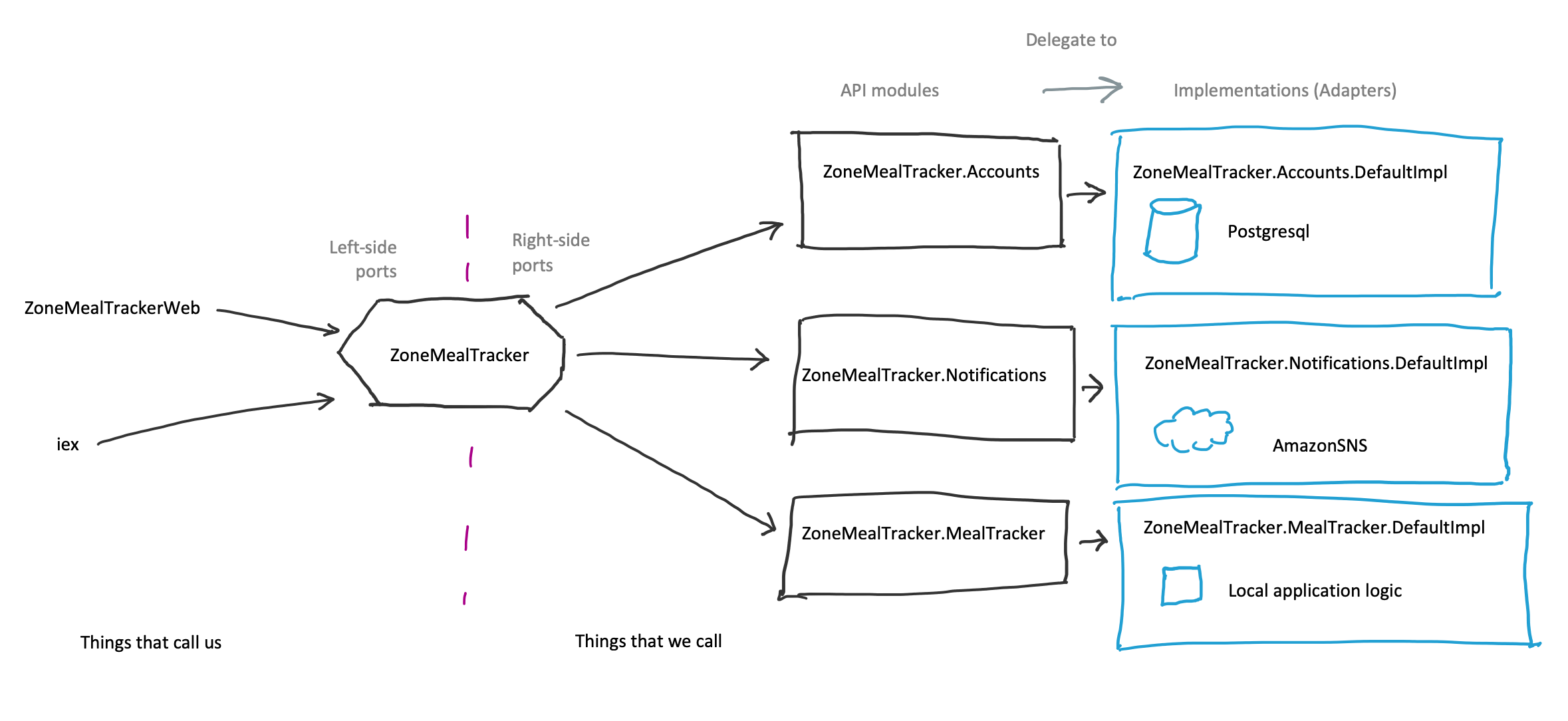
In this approach the client code remains the same.
@spec register_user(String.t(), String.t()) ::
{:ok, User.t()} | {:error, :email_already_registered}
def register_user(email, password) do
case AccountStore.create_user(email, password) do
{:ok, %User{id: user_id} = user} ->
:ok = Notifications.set_user_email(user_id, email)
:ok = Notifications.send_welcome_message(user_id)
{:ok, user}
{:error, :email_not_unique} ->
{:error, :email_already_registered}
end
end
The collaborating module is where the adjustment is made.
defmodule ZoneMealTracker.AccountStore do
@moduledoc false
alias ZoneMealTracker.AccountStore.User
@behaviour ZoneMealTracker.AccountStore.Impl
@impl true
@spec create_user(User.email(), User.password()) ::
{:ok, User.t()} | {:error, :email_not_unique}
def create_user(email, password) do
impl().create_user(email, password)
end
defp impl do
Application.get_env(:zone_meal_tracker, :account_store, __MODULE__.PostgresImpl)
end
end
Then the actual implementation is moved into its own module.
defmodule ZoneMealTracker.AccountStore.PostgresImpl do
@moduledoc false
alias Ecto.Changeset
alias ZoneMealTracker.AccountStore.PostgresImpl.InvalidDataError
alias ZoneMealTracker.AccountStore.PostgresImpl.Repo
alias ZoneMealTracker.AccountStore.User
@behaviour ZoneMealTracker.AccountStore.Impl
@impl true
@spec create_user(User.email(), User.password()) ::
{:ok, User.t()} | {:error, :email_not_unique}
def create_user(email, password) when is_email(email) and is_password(password) do
%User{}
|> User.changeset(%{email: email, password: password})
|> Repo.insert()
|> case do
{:ok, %User{} = user} ->
{:ok, user}
{:error, %Changeset{errors: errors}} ->
if Enum.any?(errors, &match?({:email, {"is_already_registered", _}}, &1)) do
{:error, :email_not_unique}
else
raise InvalidDataError, errors: errors
end
end
end
end
Finally the API and implementations are kept in sync with a behaviour.
defmodule ZoneMealTracker.AccountStore.Impl do
@moduledoc false
alias ZoneMealTracker.AccountStore.User
@callback create_user(User.email(), User.password()) ::
{:ok, User.t()} | {:error, :email_not_unique}
end
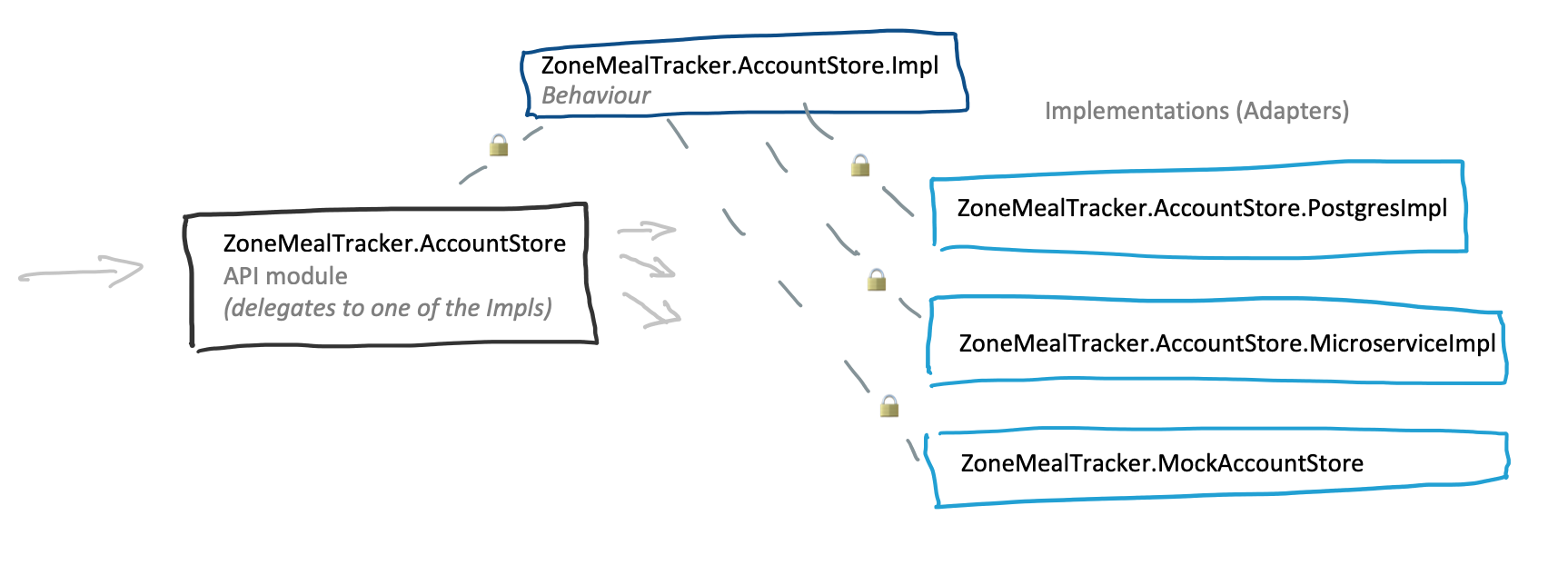
Benefits
- Doesn’t require changing client code
- Dialyzer works
- Single place to swap implementations
- Compatible with Mox
- The extra namespace makes it easy to keep multiple implementations separate. Each implementation will have its own namespace, and deleting an implementation is as easy as deleting its namespace.
Drawbacks
- Requires more scaffolding
- Adds an extra level to the namespace hierarchy
- The current implementation is controlled globally via the application environment. This makes it difficult for multiple implementations to be run in parallel.
The “Calling an API module that delegates to the current implementation behind the scenes” approach is the one that I’ve found to work best and is the approach I’ll be using for the rest of this article.
Unit Testing
With the swapping mechanism in place, now we can easily test ZoneMealTracker in isolation without having to set up (or even have the implementation completed for) ZoneMealTracker.AccountStore or ZoneMealTracker.Notifications.
Below is the ZoneMealTracker module, along with its tests.
# lib/zone_meal_tracker.ex
defmodule ZoneMealTracker do
@moduledoc """
Public API for ZoneMealTracker
"""
alias ZoneMealTracker.AccountStore
alias ZoneMealTracker.Notifications
@spec register_user(String.t(), String.t()) ::
{:ok, User.t()} | {:error, :email_already_registered}
def register_user(email, password) do
case AccountStore.create_user(email, password) do
{:ok, %User{id: user_id} = user} ->
:ok = Notifications.set_user_email(user_id, email)
:ok = Notifications.send_welcome_message(user_id)
{:ok, user}
{:error, :email_not_unique} ->
{:error, :email_already_registered}
end
end
end
# test/test_helper.exs
Mox.defmock(ZoneMealTracker.MockAccountStore,
for: ZoneMealTracker.AccountStore.Impl
)
Application.put_env(
:zone_meal_tracker,
:account_store,
ZoneMealTracker.MockAccountStore
)
Application.put_env(
:zone_meal_tracker,
:notifications_impl,
ZoneMealTracker.MockNotifications
)
Mox.defmock(ZoneMealTracker.MockNotifications,
for: ZoneMealTracker.Notifications.Impl
)
# test/zone_meal_tracker.exs
defmodule ZoneMealTrackerTest do
use ExUnit.Case, async: true
import Mox
alias ZoneMealTracker
alias ZoneMealTracker.MockAccountStore
alias ZoneMealTracker.MockNotifications
alias ZoneMealTracker.User
setup [:set_mox_from_context, :verify_on_exit!]
test "register_user/2 when email is unique" do
email = "[email protected]"
password = "password"
user_id = "123"
user = %User{id: user_id, email: email}
expect(MockAccountStore, :create_user, fn ^email, ^password ->
{:ok, user}
end)
MockNotifications
|> expect(:set_user_email, fn ^user_id, ^email -> :ok end)
|> expect(:send_welcome_message, fn ^user_id -> :ok end)
assert {:ok, ^user} = ZoneMealTracker.register_user(email, password)
end
test "register_user/2 when email is already taken" do
email = "[email protected]"
password = "password"
expect(MockAccountStore, :create_user, fn ^email, ^password ->
{:error, :email_not_unique}
end)
assert {:error, :email_already_registered} = ZoneMealTracker.register_user(email, password)
end
end
Since we have clear APIs for each of our dependencies and an easy way to
swap in mock implementations, it’s very easy to unit test our business logic
at the same level of abstraction the code was written at. With mock implementations
swapped in, we can easily test that no notification is sent when
AccountStore.create_user/2 returns {:error, :email_not_unique}. The mock saves
us from having to first create a user in the database with the same email, so we
could ensure the second user registration failed and no notifications were sent on failure.
Instead, this approach allows us to unit test our layers in isolation and relies on our
contracts between modules (APIs) — enforced by dialyzer, the AccountStore.Impl behaviour
and double-checked by integration tests — to ensure the modules work together as expected.
This approach allows higher layers to focus on testing known responses from lower layers
without being coupled to details of the underlying implementation. Furthermore, if the
account store is migrated from a local postgres-based implementation, to a high-availability
riak-based implementation, the business logic tests in ZoneMealTracker don’t have to be
modified to be compatible with the new ZoneMealTracker.AccountStore implementation.
Swappable layers all the way down
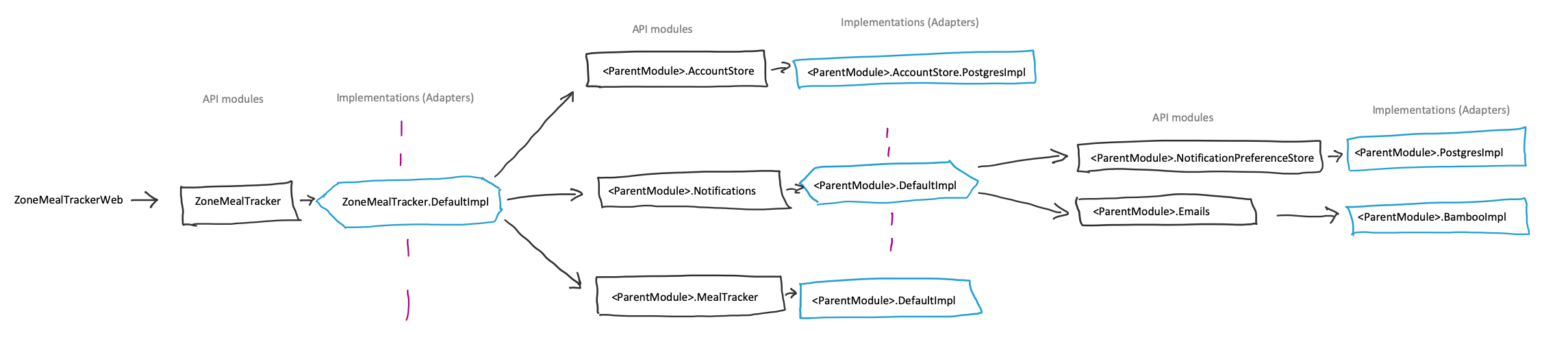
Although the scope of Hexagonal Architecture is limited to saying that business logic inside a hexagon should communicate to each outside system over a well-defined API, this pattern also lends itself to being repeated at multiple layers throughout the application. If we allow for swappable implementations at each layer, we end up with a tree of neatly layered dependencies, all having implementations that can be easily replaced at any point. Not only does this significantly help in testing, but it lets the tests for each layer focus on its own level of abstraction without being coupled to the underlying implementation. For example, the tests for ZoneMealTracker.Notifications.send_welcome_message/1 ensure if an email address is registered for the given user id, a welcome email is sent to that address. Because we can swap in mocks for the NotificationPreferenceStore and Emails modules, our tests won’t be coupled to how notification preferences are stored or how emails are delivered. Instead, they will be able to focus on the business logic of an email being sent to the appropriate user when the function is called.
File Structure mirrors application structure
Another great thing about this pattern is it makes the separation between public API modules and their underlying implementations even more clear.
lib/zone_meal_tracker/
account_store.ex <- Top level API module
account_store/
impl.ex <- Behaviour to be implemented by top level module and impls
in_memory_impl.ex <- An in-memory implementation
in_memory_impl/ <- modules used only by this specific implementation
state.ex
login.ex <- struct returned by public API
postgres_impl.ex <- A postgres-backed implementation
postgres_impl/ <- modules used only by this specific implementation
domain_translator.ex
exceptions.ex
login.ex
repo.ex
supervisor.ex
user.ex
supervisor.ex <- Helper module used across all implementations (@moduledoc false)
user.ex <- struct returned by public API
When looking through a module’s folder, there are a few things that should stand out:
- Anything ending in
_implis an implementation. Anything inside the<impl_name>_impl/folder is a helper module used only by that implementation impl.exis the behaviour that keeps the top level module and implementations in sync.- Most other modules in the folder (with the exception of well known modules like
application.exorsupervisor.ex) will be struct-only modules that are referenced by the API.
This structure and uniformity makes it easy to understand a layer just by glancing at the file tree. Furthermore, we may have started out with an InMemoryImpl and expanded to a PostgresImpl as we improved our understanding of the API we needed to provide. This structure allows the PostgresImpl to be developed in isolation while the InMemoryImpl is still being used. When it’s time to switch from the InMemoryImpl to the PostgresImpl, it can be done with a single line change in the top level module that sets the default implementation to PostgresImpl (it could also be changed via the application environment to allow for easy rollback). Once the migration is complete and we’re ready to remove the old implementation, the only thing that needs to be done is to delete in_memory_impl.ex and in_memory_impl/. Since the entire implementation is contained in that file and folder, removing it is extremely simple. This idea was originally inspired by Johnny Winn’s talk: Just Delete It.
Integration testing
Although each layer has been fully unit tested and dialyzer is running type checking between the layers, it is still important to do some end-to-end tests to ensure all of the default implementations integrate as expected. This could be a simple as writing an automated test that goes through the user registration flow to ensure everything works as expected.
Since our tests manipulate the application environment to swap in mock implementations at various layers, it’s generally best to have an integration tester outside of the umbrella app that starts the app in a clean environment.
There is an example integration tester in the
integration_testerfolder of the ZoneMealTracker app
If you need to do browser-based integration testing, Wallaby and Hound are great tools that allow you to drive your app via a real web browser. If you’re writing an app with an API, it’s worth considering building an API client to make integration testing easier (it’s also very helpful when it’s time to call your API from another elixir application).
Tips and tricks
Although this pattern works very well and gives you flexibility when maintaining a long lived application, there are a few items to keep in mind when working in an application with this sort of structure.
Only add swapping mechanisms when needed
When first starting out, it’s tempting to add swapping mechanisms between every module. Unfortunately, too many swapping mechanisms will only bring needless pain and frustration. Only insert swapping between:
- A business logic layer and a layer that reaches out to an external service (API, database, etc)
- Distinct business logic layers. For example, a developer could insert a swapping mechanism for
ZoneMealTracker.Notificationsso its parent layer,ZoneMealTracker, could be tested in isolation. When testingZoneMealTracker, we don’t care how notifications are sent, just that the appropriate function is called onZoneMealTracker.Notifications.
Many times, there are other helper modules like ZoneMealTracker.Notifications.Logger.Formatterthat contain only pure functions that have been extracted from their parent (ZoneMealTracker.Notifications.Logger). These modules don’t interact with any external services or parts of the system and therefore don’t need swapping logic. Adding swapping logic to these modules would only complicate testing and the overall application structure.
Keep implementation details out of APIs
It’s also important to not let implementation details leak into the app’s APIs. If a developer isn’t disciplined and returns Ecto schemas and changesets in their API, they may not be able to swap out their ecto-based local accounts store, with a new implementation that reaches out over HTTP to an accounts microservice. The key is to ensure structs that are accepted or returned via the public API don’t have any coupling to the underlying implementation. This means no Ecto schemas or changesets should leak out into the public API because they would prevent us from switching to a non-ecto data store.
Working with long namespaces
After we’ve started layering our application into the appropriate levels of abstraction (complete with swapping logic), there are times that our namespaces can get very deep. When nesting 3 or more swappable layers, module names can get very long and cumbersome.
defmodule ZoneMealTracker.DefaultImpl.Notifications.DefaultImpl
.NotificationPreferenceStore.PostgresImpl.PrimaryEmail do
end
When that point comes, it works well to pick a logical, stand-alone layer like ZoneMealTracker.DefaultImpl.Notifications and extract it into its own application under the umbrella. To indicate it’s an internal app, I prefix the application with the project’s initials like ZMTNotifications. Not only does this extraction shorten the length of the namespaces, but it also brings several other benefits:
- Each internal app has its own mix.exs, which makes it easy to tell which layer introduces a dependency
- Standalone libraries like API clients can easily be extracted out of the umbrella into their own projects and published to Hex.
- Even on an internal application, its top level module exposes an API that the rest of the system can build on. Since this module has enough functionality that made it worth extracting, I also add documentation for this top-level internal API. Now when developers generate the ExDoc for the project, they’ll not only see the main Public API (
ZoneMealTracker), but any internal APIs they can reach for as well (likeZMTNotifications).
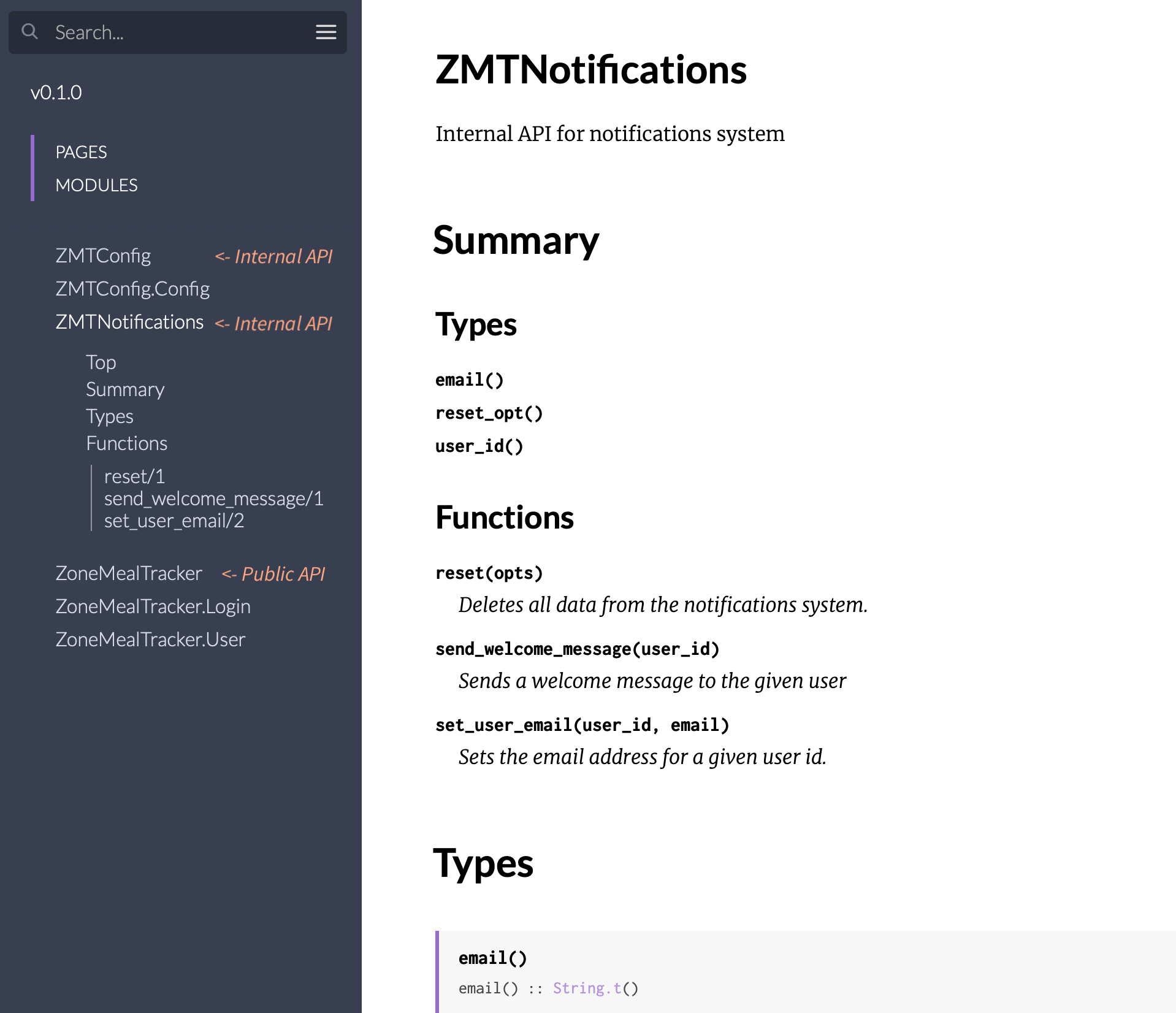
No logic in API modules
When building API modules, their functions should only be passthroughs to the current implementation. If a developer adds logic to an API module, they are forced to also keep this logic in mind when they want to return specific data from a function. Here is an example:
# API Module that contains logic
defmodule ZMTNotifications do
@spec fetch_registered_email(String.t()) | {:ok, String.t()} | {:error, :not_found}
def fetch_registered_email(email) do
current_impl().fetch_registered_email(
end
@spec email_registered?(String.t) :: boolean
def email_registered?(email) do
# This contains logic instead of a passthrough
match?({:ok, _}, fetch_email_registered(email)
end
end
# Module being tested
defmodule ZoneMealTracker do
@spec email_registered?(String.t) :: boolean
def email_registered?(email) do
# Code under test
ZMTNotifications.email_registered?(email)
end
end
# Test Case
defmodule ZoneMealTrackerTest do
use ExUnit.Case
import Mox
alias ZoneMealTracker.MockZMTNotifications
test "email_registered?/1 returns true when email is registered" do
# Although the code under test is calling
# `ZMTNotifications.email_registered?/1`, we have to know to mock
# `fetch_registered_email/1` because there is logic in
# `ZMTNotifications.email_registered?/1` instead of being just a straight
# passthrough.
expect(MockZMTNotifications, :fetch_registered_email, fn email -> {:ok, email})
assert ZoneMealTracker.email_registered?("[email protected]")
end
end
From the example above, instead of being able to simply expect that MockZMTNotifications.email_registered?/1 returned the value we wanted, we need to know that the underlying implementation calls MockZMTNotifications.fetch_registered_email/1. In order to make MockZMTNotifications.email_registered?/1 return true, we actually have to make MockZMTNotifications.fetch_registered_email/1 return {:ok, email}. This is a lot of unnecessary coupling and complication to test a seemingly simple function.
The only bit of logic I would put in an API module would be guard clauses to ensure the appropriate data types are passed to the underlying implementation. This makes error messages nicer when calling functions on an API module with invalid data and keeps us from forgetting guard clauses on our actual implementations. Other than that, functions on an API module should be a complete pass-through to the current implementation.
Relationship to prior works
In software design, most ideas are applying somebody’s earlier work in a slightly different context. Greg Young’s “The art of destroying software” is an excellent talk where he discusses composing large systems out of a collection of tiny programs (components) — each of which can be deleted and rewritten in about a week. This helps keep parts of larger systems, small, understandable and easily adaptable to changing business requirements.
The idea of Application Layering meshes extremely well with this philosophy. With Application Layering, we build the application as a tree of components that can be swapped out at any time. For example, if we want to change the ZMTNotifications.DefaultImpl.NotificationPreferenceStore to write to a riak database instead of a postgres database, we can write a new ZMTNotifications.DefaultImpl.NotificationPreferenceStore.RiakImpl module and swap it in when it’s ready. When the transition from postgres to riak is complete, we can delete ZMTNotifications.DefaultImpl.NotificationPreferenceStore.PostgresImpl and all of its child modules. By having our database logic isolated into a small component, we can easily follow Greg’s idea of being able to delete and rewrite a component in about a week.
To take this one step further, when business requirements change, we may find that we need to completely change the design of the notification system. With our existing swapping infrastructure in place, we can define a new ZMTNotifications.EnhancedImpl module and start work on the new, improved notifications system. This implementation may need separate data stores and services than the ZMTNotifications.DefaultImpl implementation, but they can all be tucked under the ZMTNotifications.EnhancedImpl namespace. As long as it can fulfill the contract defined by the ZMTNotifications.Impl behaviour, we’re free to rewrite this tree of components without affecting any upstream layers. Also, because this component is isolated from the rest of the system, in many cases it can also be rewritten in about a week.
In Greg’s talk he mentions the benefits of being able to rewrite any of the tiny programs (components) within an application in a week. In Application Layering, each swappable implementation is analogous to one of those tiny programs. Greg mentions “the difference between great code and sucky code is the size of the programs (layers).” If each layer is focused only on a single level of abstraction (business logic, persistence, etc), each layer stays small and can be easily replaced as requirements change. This sort of structure unshackles developers from their large, complex codebases and gives them freedom to rewrite small parts of their system as changes are needed. From my experience, this makes for an extremely enjoyable application to work in.
Final advice
Building software is a process — the proper software design will be come apparent as you go. Many times I’ve tried to skip steps and create layers before I actually need them, only to realize I’ve chosen wrong and need to rewrite my code. This is why I try to follow the following process:
- Public functions should be made easier to read by extracting private functions
- If several related private functions have been extracted or I need to write unit tests for these private functions, I’ll extract them into a child module.
- If tests for my business logic are difficult to write because they require calls to an external service or separate section of business logic, I’ll insert a swappable layer at the module that serves as a boundary between my business logic and the external service/separate domain.
It also helps when writing a module to ask myself “what is this module’s Public API?” This helps me to think about the contract I need to fulfill to support the rest of the system, while giving me the flexibility to experiment with the implementation. When working in higher layers, I’ll call functions that I wish a child layer had, and then go implement the lower-level logic once I’ve solidified that child layer’s API. This helps me make sure my child layer APIs make sense.
Although it takes thought and discipline to design a system this way, it leads to an amazingly flexible codebase that is easy to adapt and maintain. I’d encourage everyone with a non-trivial application to try this pattern at some edge of your application. This could either be at a boundary to an external service (like an API client), or at the top-most boundary of your application (between the web layer and business logic). With time, you’ll figure out the ins and outs of what works and how to best structure your system. Ultimately, if done correctly, you should end up with a flexible, adaptable codebase. That said, don’t forget to add some full stack integration tests to ensure your application continues to function as you restructure your codebase.
Happy coding!
Resources
- Growing Applications and Taming Complexity - Aaron Renner - ElixirConf 2018
- ZoneMealTracker repo
- Alistair in the “Hexagone”