Building Workflows with Sidekiq Batches
A few weeks ago, Sidekiq’s creator, Mike Perham, posted a great article about how to handle Really Complex Workflows with Batches. His article shows how you can wait for a batch of jobs to complete before moving on to the next job/batch in the workflow.
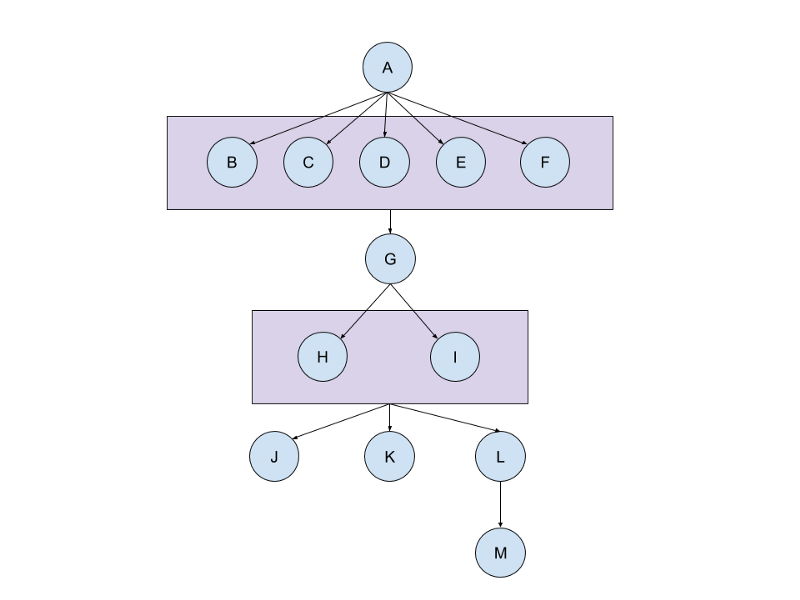
I first learned about this technique during Sidekiq’s weekly happy hour back in March, and have been using it on Recognized.io for the last 6 months. Although the example in the documentation shows the basics of dependent batches, I wanted to share how we created standalone Workflow classes to manage this process.
Here is an example of a workflow class using Sidekiq’s batch callbacks.
class GenerateComplexReportWorkflow
include Sidekiq::Worker
# The main entry point into the workflow, just
# like a normal Sidekiq job
def perform(report_id)
step_1(report_id)
end
def step_1(report_id)
generate_calculations_batch = Sidekiq::Batch.new
generate_calculations_batch.on(
"success", #{self.class}#step2",
"report_id" => report_id
)
generate_calculations_batch.jobs do
Customer.find_each do |customer|
ExpensiveCalculationForCustomer.perform_async(
report_id, customer.id
)
end
end
end
def step_2(status, options)
report_id = options["report_id"]
generate_summaries_batch = Sidekiq::Batch.new
generate_summaries_batch.on(
"success", #{self.class}#step3",
"report_id" => report_id
)
generate_summaries_batch.jobs do
Region.find_each do |region|
ExpensiveRegionalSummary.perform_async(
report_id, region.id
)
end
end
end
def step_3(status, options)
report = Report.find(options["report_id"])
report.mark_as_finished!
end
end
The key thing to notice is we set a success callback on the batch that triggers the next step in the
workflow. This callback also passes along report_id, which is needed in subsequent steps:
generate_calculations_batch.on(
"success", "#{self.class}#step2",
"report_id" => report_id
)
Gotchas
When we start using #each to dynamically create jobs in a workflow, there are a few edge cases that make things tricky.
No Jobs in a Batch
In the code below, if there aren’t any customers, it won’t generate any jobs for the batch.
generate_calculations_batch.jobs do
Customer.find_each do |customer|
ExpensiveCalculationForCustomer.perform_async(
report_id, customer.id
)
end
end
I found out the hard way if there are no jobs in a batch, the callbacks won’t run and trigger
next step in the workflow. To fix this, we add a NullWorker job to the batch, which ensures
we always have at least one job and the callbacks will be run.
class NullWorker
include Sidekiq::Worker def perform
#NOOP
end
end
class GenerateComplexReportWorkflow
def step_1(report_id)
# omitted...
generate_calculations_batch.jobs do
Customer.find_each do |customer|
ExpensiveCalculationForCustomer.perform_async(
report_id, customer.id
)
end
# Ensure batch has at least 1 job so callbacks
# are run.
NullWorker.perform_async
end
end
# other steps omitted...
end
Adding a large number of jobs to a batch
Sometimes you need to create a large number of jobs (500,000+) in a single batch. Since all
jobs defined in a jobs block are created atomically, it can take a few minutes to persist
your batch in Redis. With enough jobs, this can even lead to a Redis time out error.
Fortunately, you can add jobs to your batch in groups. Here’s an example:
class GenerateComplexReportWorkflow
def step_1(report_id)
# omitted...
Customer.all.pluck(:id).each_slice(1000) do |customer_ids|
generate_calculations_batch.jobs do
customer_ids.each do |customer_id|
ExpensiveCalculationForCustomer.perform_async(
report_id, customer_id
)
end
end
end
# Add one last job to make sure the callbacks are run
generated_calculations_batch.jobs do
NullWorker.perform_async
end
end
# other steps omitted...
end
There are a couple of things to note in this example. First, we use Customer.all.pluck(:id) to only load
the relevant customer ids, instead of the entire customer object. This saves a ton of time and memory.
Second, we slice the customer ids into groups, so jobs can be added to the batch in smaller groups and not stress out Redis. This also allows your workers to get started on processing a batch while the rest of the jobs are still being created. It’s important to note if all of your jobs complete before the next set of jobs have been created, your batches’ callbacks will be triggered prematurely. However, if you are using background processing to handle heavy computation, the jobs will almost always take longer to complete than the time it takes to add another set of jobs to the batch.
Finally, we add our NullWorker job to the batch to make sure the callbacks are run, even if there is no data in the system.
I have been using this approach on Recognized.io for the past several months and it’s allowed me to create some very large batches without issue.
Wrapping Up
Sidekiq Pro’s batch support enables developers to achieve maximum parallelization, while sending jobs through complex workflows. Although it’s a paid addon, it’s highly worth the money when you consider the significant performance improvements you’ll be able to make on your app.
Originally published at blog.animascodelabs.com on December 28, 2015.